
Interface, API, prompts, stratégie créative. Un guide pratique pour directions créatives, studios et équipes marketing.
Ce document est est écrit pour trois lecteurs : les directeurs et directrices de création qui veulent comprendre ce qui bascule dans la taxinomie du travail visuel. Les équipes marketing et communication qui cherchent à intégrer GPT-Image-2 dans leur production. Les développeurs et studios qui veulent maîtriser l’API pour construire des systèmes créatifs.
Lisez-le dans l’ordre si vous découvrez le modèle. Sautez aux parties API ou pricing si vous cherchez une réponse précise. Gardez le glossaire sous la main. Bonne lecture.
TL;DR exécutif
Dix points à retenir si vous n’avez que cinq minutes.
- Le modèle s’appelle gpt-image-2. Il a été déployé officiellement le 21 avril 2026 via ChatGPT, Codex et l’API OpenAI.
- Sora est mort. Les expériences web et applicatives Sora s’arrêtent le 26 avril 2026, l’API le 24 septembre 2026. OpenAI concentre ses ressources sur l’imagerie statique contrôlable.
- Rendu typographique quasi parfait. Le modèle écrit du texte lisible, cohérent en police, et supporte plus de 80 langues en génération visuelle. Fin d’un problème historique des modèles de diffusion.
- Deux modes. Mode Instantané rapide pour tout le monde, Mode Réflexion exclusif Plus/Pro/Business, qui fait de l’auto-évaluation itérative et peut interroger le web en temps réel.
- Éditeur in-painting natif. Sélection spatiale plus instructions textuelles, dans la conversation. Retouche localisée sans Photoshop.
- Ratios flexibles. De 3:1 à 1:3, avec toutes les résolutions standards (1024×1024, 1536×1024, 2560×1440, 3840×2160).
- Deux API. Image API classique sans état pour la génération directe. Responses API avec orchestration, File IDs, tool calling et gestion de contexte pour les workflows avancés.
- Contraintes de taille strictes. Multiples de 16, côtés inférieurs à 4000 pixels, ratio bord long sur bord court plafonné.
- Tarification par tokens. 8 $ en entrée image et 30 $ en sortie image par million de tokens en standard. Mode Batch à moitié prix. Coût marginal par image 1024×1024 entre 0,006 $ et 0,211 $ selon la qualité.
- KYC obligatoire. Accès API commercial conditionné à une vérification d’identité institutionnelle rigoureuse.
Partie I. Ce qui a changé
1. La bascule d’avril 2026
Deux annonces le même mois. Leur lecture combinée dit plus que chacune prise séparément.
D’un côté, la sortie de ChatGPT Images 2.0 (nom produit) reposant sur gpt-image-2 (nom technique). De l’autre, la fermeture programmée de Sora, le modèle vidéo. Les expériences Sora web et app s’éteignent le 26 avril 2026. L’API Sora est dépréciée le 24 septembre 2026.
Cette double décision n’est pas un accident de calendrier. C’est un signal.
OpenAI assume que la valeur industrielle de la génération visuelle ne se trouve pas dans le mouvement aléatoire et spectaculaire, mais dans le contrôle de l’image statique, éditable, cohérente, intégrable. Ce que les entreprises achètent, ce n’est pas un démonstrateur. C’est un flux de production fiable.
GPT-Image-2 assume ce positionnement. Il est livré comme une infrastructure de production d’actifs visuels de qualité commerciale. Typographie lisible, cohérence multi-images, intégration conversationnelle, API robuste. Chaque couche sert le même objectif. Sortir des images prêtes à l’emploi.
Pour les studios, les agences et les marques, cela veut dire une chose. Ce qui hier nécessitait une chaîne de production (brief, illustrateur, retoucheur, chef de projet, validation) devient, pour une part non négligeable, une conversation.
2. L’image comme langage structuré
Prompt test (image + texte) :

Create a personal brand guidelines document and detailed info about how to visually represent the universe of this woman (Monique is a French art director) : her wardrobe, her favorite objects, activities, and how she speaks and acts.Image générée (21:9) :
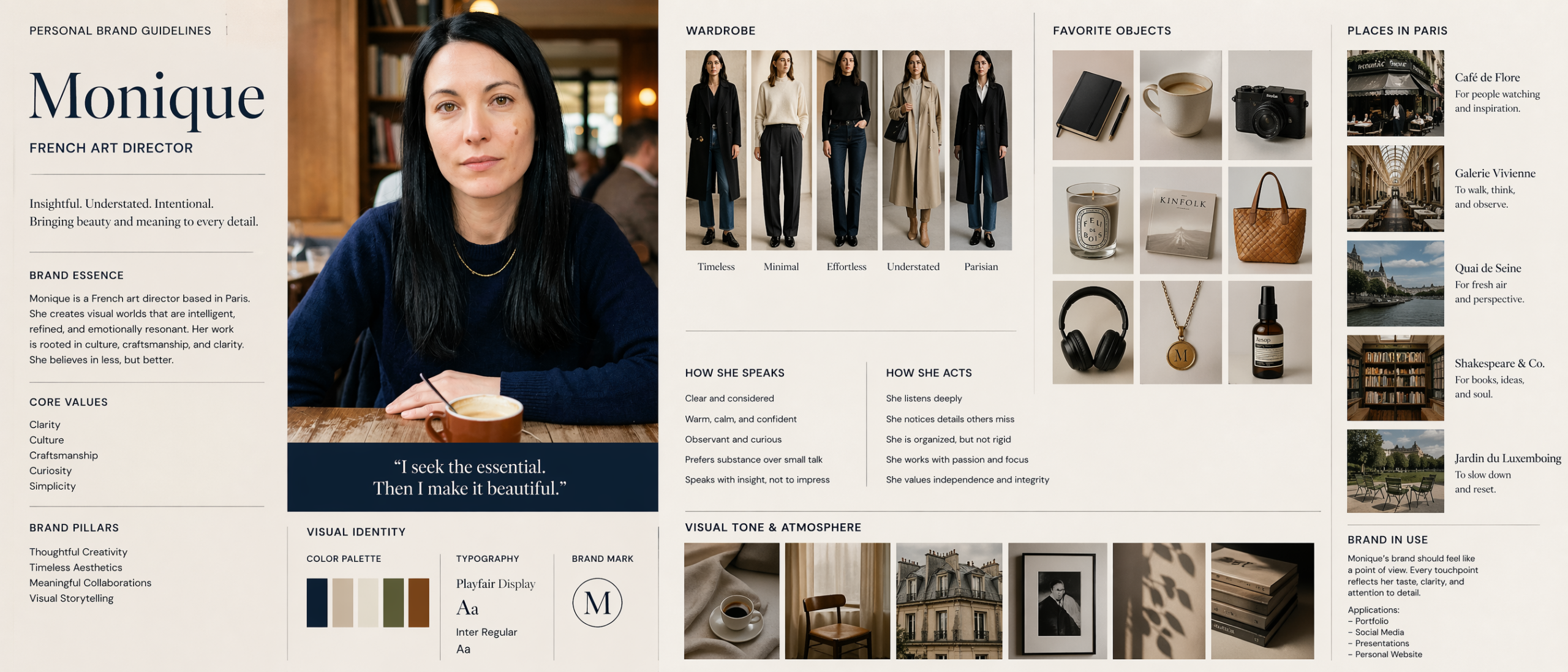
Le postulat qui sous-tend le modèle est théorique autant que technique.
L’image n’est plus traitée comme un résultat esthétique à générer, mais comme une structure sémantique à composer. Un bouton, une étiquette, un titre, un sous-titre, une zone de texte dans une affiche, un axe dans un diagramme. Chaque élément est une unité que le modèle organise, hiérarchise et relie.
Ce glissement change tout.
Il explique pourquoi le texte est enfin lisible. Pourquoi les maquettes d’interface sont crédibles. Pourquoi les infographies denses fonctionnent. Le modèle ne peint plus des formes qui ressemblent à du texte. Il compose des textes qui occupent des formes.
Il explique aussi pourquoi le modèle peut justifier une architecture de raisonnement (Mode Réflexion) pour s’auto-évaluer. Quand on traite l’image comme un énoncé, on peut en vérifier la cohérence syntaxique et sémantique.
Pour un directeur de création, l’implication est directe. Le prompt cesse d’être une invocation. Il devient une spécification. La qualité du résultat dépend de la précision avec laquelle on décrit la structure voulue, pas seulement l’ambiance.
3. Capacités visuelles nouvelles
Prompt test (images + texte) :


Create a storyboard and production sheet about a short French sci-fi film where these 2 arty people are hunted by a bot on a volcano : define a large casting, create the production set and exact location, name the dystopic movie franchise, set the photography and colors universe, use the French language.Image générée (16:9) :

Typographie intégrée
Le modèle génère des étiquettes multi-mots, des bannières publicitaires, des panneaux de signalisation, des titres d’affiches et des éléments d’interface utilisateur avec un respect scrupuleux de l’orthographe demandée.
La vraie avancée est la cohérence. La même police est maintenue sur l’ensemble des éléments d’une image. Les majuscules, minuscules et ponctuations sont gérées correctement. Les ligatures complexes, les accents et la plupart des caractères spéciaux passent.
Conséquence pratique. On peut désormais produire en direct des affiches éditoriales, des maquettes logicielles, des captures d’écran photoréalistes, des infographies denses, des bannières et des éléments de présentation.
Rendu multilingue
Le modèle gère formellement plus de 80 langues en génération visuelle et comprend des requêtes textuelles dans plus de 95 idiomes, dialectes régionaux inclus.
La qualité du rendu visuel dépend de la profondeur des données d’entraînement. Le tableau ci-dessous résume les trois niveaux de compétence typographique.
| Niveau | Langues représentatives | Impact pratique |
|---|---|---|
| Haute compétence | Anglais, espagnol, français, allemand, chinois mandarin, portugais, russe, japonais, coréen, arabe, italien, néerlandais, polonais, turc, hindi | Rendu parfait pour affiches, bannières, diagrammes. Cohérence totale des polices |
| Compétence modérée | Suédois, norvégien, danois, finnois, tchèque, roumain, grec, hébreu, thaï, vietnamien, indonésien, bengali, tamoul | Textes lisibles, corrections ponctuelles via in-painting pour ligatures ou accents complexes |
| Compétence limitée | Swahili, amharique, somali, afrikaans, basque, maltais, langues celtiques | Reconnaissance textuelle basique. Distorsions possibles sur les longues phrases |
Pour une agence internationale, cela signifie qu’on peut concevoir une campagne multiculturelle à partir d’un point central. Une même composition décline ses textes en mandarin, coréen ou arabe, en ajustant automatiquement le sens de lecture et l’équilibre visuel.
Composition spatiale et cohérence interne
Le modèle a été restructuré pour gérer la composition spatiale tridimensionnelle. Les objets occupent des positions cohérentes. Les ombres suivent la lumière. La profondeur de champ reste stable quand on fait de l’édition locale.
C’est cette cohérence qui permet les usages industriels. On peut éditer une image en retirant un élément, le modèle reconstruit l’arrière-plan occulté avec une texture, un éclairage et une profondeur alignés sur l’image d’origine.
Partie II. Les deux modes de génération
4. Mode Instantané contre Mode Réflexion
GPT-Image-2 introduit une dichotomie architecturale que les générations précédentes ne connaissaient pas. Deux modes coexistent, avec des logiques radicalement différentes.
Mode Instantané
Disponible pour tous les utilisateurs de ChatGPT, y compris les comptes gratuits. Il déploie gpt-image-2 dans une boucle de rétroaction extrêmement rapide. Le prompt entre, l’image sort. Latence typique de quelques secondes.
C’est le mode adapté à l’idéation, aux variations, à la production en volume, aux cas où la vitesse prime sur la précision absolue.
Mode Réflexion
Réservé aux abonnés Plus, Pro et Business. Il transforme la génération en tâche stratégique.
Quand une requête arrive, le système ne déclenche pas immédiatement la diffusion. Il mobilise les modèles d’inférence de la série O pour analyser la demande, fragmenter la composition, interroger des bases de données en temps réel via une recherche web intégrée, combler les lacunes factuelles.
Puis il génère silencieusement entre 5 et 10 itérations internes, les compare au prompt initial, détecte les anomalies spatiales ou typographiques, et relance des corrections jusqu’à satisfaction.
Résultat. Des images plus précises, plus fidèles, plus cohérentes. Au prix d’une latence supérieure et d’un coût par image qui peut être dix fois plus élevé.
Prompt test (image + texte) :

Create a brand guidelines document with detailed info about an edgy fish restaurant located on this beach in the south of France: selected natural materials, minimal architecture, dimensions, name, graphic and tone guidelines, dishes and their names.Image générée (2:3) :

5. Quand utiliser quoi
La question n’est pas théorique. C’est une décision économique et créative à prendre à chaque production.
| Cas d’usage | Mode recommandé | Raison |
|---|---|---|
| Idéation et moodboard | Instantané | Volume et rapidité priment |
| Variations sur un même concept | Instantané | Le prompt est stable, on cherche de la diversité |
| Hero shot de campagne | Réflexion | Qualité absolue non négociable |
| Série multi-images cohérente | Réflexion | Le modèle bénéficie de l’auto-évaluation pour maintenir la cohérence |
| Infographie scientifique validée | Réflexion | Recherche web utile pour la précision factuelle |
| Maquette UI exploratoire | Instantané | Itération rapide sur la structure |
| Maquette UI finale de brief | Réflexion | Le détail typographique mérite l’auto-correction |
| Production de masse basse valeur | Instantané | Coût unitaire compatible avec le volume |
| Visuel éditorial magazine | Réflexion | Composition dense, typographie critique |
| Test de prompt en ingénierie | Instantané | On itère sur la formulation avant d’investir en Réflexion |
Règle de studio. Itérer en Instantané jusqu’à ce que le prompt soit verrouillé. Basculer en Réflexion uniquement pour la passe finale.
Partie III. Interface ChatGPT
6. Le workflow conversationnel
L’intégration native de gpt-image-2 dans ChatGPT est la transformation la plus visible pour les utilisateurs non développeurs. Elle fusionne génération et édition dans un même flux.
Génération initiale
On décrit l’image dans la conversation. Le modèle propose une ou plusieurs compositions. Le prompt peut inclure des contraintes de format, de style, de contenu textuel, de référence iconographique. Pas besoin de syntaxe particulière. Le langage naturel suffit.
Astuce de prompt. Toujours nommer la fonction de l’image avant son style. Une affiche événementielle n’a pas la même structure qu’une bannière web ni qu’une illustration éditoriale. Le modèle adapte la composition à la fonction si on la précise.
Itération et variation
Une fois une image produite, la conversation permet d’itérer sans repartir de zéro. On peut demander une variation, un recadrage, un changement de palette, un ajout d’élément. Le modèle conserve le contexte compositionnel et ne reconstruit pas tout.
Transformation globale
On peut demander des transformations globales sans outil de sélection. Transformer une photographie en illustration de bande dessinée, changer l’ambiance lumineuse, inverser une palette. Le modèle maintient la structure compositionnelle.
Prompt test :
Create a detailed futuristic driving interface dashboard of flying french DS 2036, including dataviz and brain control, multiple dashcams, AI controls with a nostalgic touch.Image générée (21:9) :

7. L’éditeur in-painting intégré
L’éditeur visuel est l’innovation qui rend obsolète une partie du travail de retouche matricielle. Il se déclenche au clic sur une image générée dans la conversation.
Sélection spatiale
Une fenêtre modale s’ouvre avec l’image en grand et un outil de surlignage. On dessine une zone avec le curseur. Ce masque n’a pas besoin d’être précis au pixel. Le modèle s’octroie la liberté algorithmique de déborder légèrement de la zone si la cohérence visuelle l’exige.
Instruction textuelle locale
Une fois la zone sélectionnée, on tape ce qu’on veut à la place. « Ajouter un logo Nike sur cette casquette. » « Retirer cette personne en arrière-plan. » « Changer la couleur de cette voiture en vert forêt. »
Le réseau de neurones interprète l’instruction en conjonction avec le masque et régénère les pixels ciblés. Il reconstruit les parties occluses en cohérence avec la texture, l’éclairage et la profondeur de champ de l’image originale.
Limites utiles à connaître
Le surlignage ne garantit pas une délimitation mathématique absolue. Sur des objets aux contours complexes (cheveux, fumée, reflets), le résultat est souvent meilleur si on laisse le modèle déborder plutôt que de chercher à le contraindre.
L’éditeur n’est pas un substitut complet à un logiciel de retouche professionnelle. Pour un détourage parfait, un canal alpha natif ou une gestion colorimétrique critique, un passage Photoshop reste nécessaire.
8. Gestion flexible des ratios d’aspect
Fini le carré 1:1 obligatoire. Le modèle génère nativement dans une large gamme de ratios.
| Ratio | Label | Usage type |
|---|---|---|
| 1:1 | Carré | Réseaux sociaux généralistes, avatars |
| 3:2 | Paysage classique | Illustration d’article de presse |
| 2:3 | Portrait | Affiches, mobile, couvertures |
| 16:9 | Widescreen | Bannières web, écrans, vidéo |
| 9:16 | Vertical | Stories, reels, TikTok |
| 3:1 | Panorama ultra-large | En-tête de site, hero banner étendu |
| 1:3 | Portrait allongé | Formats éditoriaux verticaux |
Cette flexibilité couvre l’intégralité du spectre social, éditorial et publicitaire. Elle évite les recadrages post-production qui cassent la composition prévue par le modèle.
Partie IV. API et intégration technique
Prompt JSON test :
Create a 8x9 grid of a Paris icon set made of emojis (a mix of culture, art, expressions, hand signs, architecture, all without clichés), for the style use this JSON :
{
"prompt": "A futuristic high-tech reinterpretation of the emoji {EMOJI}, designed as a sleek object or character ",
"parameters": {
"artstyle": "cinematic futuristic concept design, luxury sci-fi, retro-futurism",
"material": "polished metal, glass, holographic elements, soft glowing accents",
"shape": "streamlined, aerodynamic, elegant curves inspired by high-end concept vehicles",
"lighting": "golden hour cinematic lighting with soft reflections and ambient glow",
"color": "deep rich tones with metallic highlights and subtle neon accents",
"composition": "3/4 sharp view, black background",
"rendering": "ultra-detailed photorealistic 3D render",
"details": "reflections, depth of field, cinematic framing",
"vibe": "premium, visionary, calm futuristic luxury with a touch of nostalgia"
}
}Image générée (2:3) :

9. Image API classique
L’Image API reste l’infrastructure de choix pour les architectures microservices qui n’ont pas besoin de mémoire conversationnelle. Trois points de terminaison principaux.
Generations
from openai import OpenAI
client = OpenAI()
response = client.images.generate(
model="gpt-image-2",
prompt="Affiche éditoriale style magazine, typographie Didot moderne, "
"titre 'Les Nouveaux Ateliers' en haut à gauche, "
"composition minimaliste, palette crème et noir encre",
size="1024x1536",
quality="high",
output_format="png",
n=1
)
# Réponse encodée en base64
import base64
image_data = base64.b64decode(response.data[0].b64_json)
with open("affiche.png", "wb") as f:
f.write(image_data)
Edits
Permet la modification d’une image existante avec un masque de transparence.
response = client.images.edit(
model="gpt-image-2",
image=open("source.png", "rb"),
mask=open("masque.png", "rb"),
prompt="Remplacer le ciel par un coucher de soleil orangé",
size="1536x1024"
)
Variations
Génère des variantes d’une image existante sans prompt textuel. Utile pour explorer l’espace visuel autour d’une référence.
response = client.images.create_variation(
model="gpt-image-2",
image=open("reference.png", "rb"),
n=4,
size="1024x1024"
)
10. Responses API
La vraie avancée architecturale. La Responses API émule la complexité et la fluidité de l’interface conversationnelle. Elle s’appuie sur gpt-5.4 comme chef d’orchestre, qui décide d’appeler ou non l’outil de génération d’images.
Principe du tool calling
response = client.responses.create(
model="gpt-5.4",
input=[
{"role": "user", "content": "Crée une affiche pour notre nouveau parfum Oud Volcano"}
],
tools=[
{"type": "image_generation", "action": "auto"}
]
)
Le paramètre action contrôle le comportement.
action: "auto"laisse le modèle décider de générer ou d’éditer.action: "generate"force une composition nouvelle.action: "edit"force la modification d’une image ancrée dans le contexte.
Édition multi-tours via File IDs
On peut passer un fichier déjà uploadé comme référence persistante.
uploaded = client.files.create(
file=open("oud-volcano-v1.png", "rb"),
purpose="vision"
)
response = client.responses.create(
model="gpt-5.4",
input=[
{
"role": "user",
"content": [
{"type": "input_text", "text": "Garde la composition mais passe la palette en tons plus sombres"},
{"type": "input_image", "file_id": uploaded.id}
]
}
],
tools=[{"type": "image_generation", "action": "edit"}],
conversation="oud-volcano-session-042"
)
Gestion d’état et de contexte
Le paramètre conversation lie la requête à un historique spécifique. Le paramètre context_management régule la longueur de la conversation pour éviter le dépassement de la fenêtre de 272 000 tokens, avec un seuil de compaction activé par compact_threshold (valeur minimale 1000 tokens).
11. Paramètres techniques à connaître
Tableau de référence des paramètres les plus utilisés.
| Paramètre | Valeurs | Effet |
|---|---|---|
size ou image_size | « 1024×1024 », « 1536×1024 », « 1024×1536 », custom | Dimensions de sortie. Voir section 12 pour les contraintes |
quality | « low », « medium », « high », « auto » | Impact direct sur coût et temps |
output_format | « png », « jpeg », « webp » | WebP souvent par défaut pour compression |
output_compression | 0 à 100 | Qualité de compression en pourcentage (JPEG et WebP) |
background | « transparent », « opaque » | Transparence native limitée, détourage post souvent nécessaire |
moderation | « auto », « low » | Filtre de contenu sensible |
n | 1 à 10 | Nombre d’images par requête. Clé pour l’idéation |
12. Contraintes dimensionnelles
L’algorithme de diffusion impose des règles strictes pour éviter des erreurs de compilation dans les couches d’attention.
Règle 1. Longueur maximale des bords. Aucun côté ne doit dépasser 4000 pixels. Recommandation forte de rester sous 3840 pixels pour maintenir l’intégrité spatiale.
Règle 2. Modularité. Les deux dimensions doivent impérativement être des multiples de 16. Dicté par l’architecture des blocs de compression latente.
Règle 3. Proportions maximales. Le ratio entre bord long et bord court ne doit jamais dépasser un seuil fixé par l’API. Au-delà, le modèle a tendance à dupliquer les éléments visuels plutôt qu’à les étendre rationnellement.
Résolutions standard recommandées
| Label | Résolution | Ratio | Usage |
|---|---|---|---|
| Carré par défaut | 1024 x 1024 | 1:1 | Généraliste, stabilité absolue, optimisé social |
| Paysage HD | 1536 x 1024 | 3:2 | Bannières web, illustration éditoriale |
| Portrait HD | 1024 x 1536 | 2:3 | Mobile, affiches marketing |
| Haute résolution 2K | 2560 x 1440 | 16:9 | Limite supérieure de fiabilité recommandée |
| Ultra haute définition 4K | 3840 x 2160 (ajusté 3824×2144) | 16:9 | Cible expérimentale. Arrondi au multiple de 16 valide |
13. Vérification d’organisation API
L’accès commercial à la famille gpt-image (gpt-image-2, gpt-image-1.5, gpt-image-1-mini) passe par un protocole strict de vérification d’identité institutionnelle. Ce KYC algorithmique est conçu pour limiter la prolifération de la désinformation et de l’usurpation d’identité.
Documents acceptés
Documents gouvernementaux physiques originaux émis par l’une des plus de 200 juridictions prises en charge. Passeports, permis de conduire, cartes nationales d’identité, permis de résidence.
Ce qui est rejeté
Tout format numérique, capture d’écran, photocopie ou document altéré. L’intégrité physique doit être totale. Bords non coupés, photo du visage lisible, nom complet et date de naissance parfaitement visibles.
Règles anti-fraude
Un même document d’identité ne peut authentifier qu’une seule organisation dans l’écosystème OpenAI pendant une période de carence de 90 jours consécutifs.
Dépannage en cas d’échec
Les causes les plus fréquentes. Flou optique sur la photographie du document. Discordance avec le selfie en direct. Luminosité insuffisante. Angle qui tronque un bord. En cas d’échec, le système bloque temporairement les nouvelles tentatives et force l’organisation à utiliser de nouvelles clés pour relancer le processus. Prévoyez 48 à 72h de délai avant un deuxième essai.
Prompt test :
Create a contemporary graphic comic panel story of Leonardo da Vinci's most famous flying machine, including mechanical details, scenery, vignettes, and a deconstructed grid, black white and red ink, modern typography, use French language.Image générée (2:3) :

Partie V. Économie et coûts
Le mode Instantané convient aux essais rapides, aux variations et aux images simples. Le mode Réflexion devient préférable dès que le prompt demande une forte fidélité, du texte lisible, une composition complexe ou un rendu destiné à la production.
14. Matrice tarifaire
OpenAI facture à la consommation de tokens, par tranche d’un million. Deux paradigmes d’exécution, Standard (temps réel) et Batch (asynchrone 24h avec 50% de réduction).
gpt-image-2
| Mode | Modalité | Entrée | Entrée en cache | Sortie |
|---|---|---|---|---|
| Standard | Image | 8,00 $ / 1M tokens | 2,00 $ / 1M tokens | 30,00 $ / 1M tokens |
| Standard | Texte | 5,00 $ / 1M tokens | 1,25 $ / 1M tokens | 10,00 $ / 1M tokens |
| Batch | Image | 4,00 $ / 1M tokens | 1,00 $ / 1M tokens | 15,00 $ / 1M tokens |
| Batch | Texte | 2,50 $ / 1M tokens | 0,625 $ / 1M tokens | Non applicable |
gpt-image-1.5
| Mode | Modalité | Entrée | Entrée en cache | Sortie |
|---|---|---|---|---|
| Standard | Image | 8,00 $ / 1M tokens | 2,00 $ / 1M tokens | 32,00 $ / 1M tokens |
| Standard | Texte | 5,00 $ / 1M tokens | 1,25 $ / 1M tokens | 10,00 $ / 1M tokens |
| Batch | Image | 4,00 $ / 1M tokens | 1,00 $ / 1M tokens | 16,00 $ / 1M tokens |
| Batch | Texte | 2,50 $ / 1M tokens | 0,63 $ / 1M tokens | 5,00 $ / 1M tokens |
gpt-image-1-mini
| Mode | Modalité | Entrée | Entrée en cache | Sortie |
|---|---|---|---|---|
| Standard | Image | 2,50 $ / 1M tokens | 0,25 $ / 1M tokens | 8,00 $ / 1M tokens |
| Standard | Texte | 2,00 $ / 1M tokens | 0,20 $ / 1M tokens | Non applicable |
| Batch | Image | 1,25 $ / 1M tokens | 0,13 $ / 1M tokens | 4,00 $ / 1M tokens |
| Batch | Texte | 1,00 $ / 1M tokens | 0,10 $ / 1M tokens | Non applicable |
15. Mécanisme par token
Combien coûte réellement une image ?
Le coût varie fortement selon la qualité choisie. Voici un ordre de grandeur par image générée.
Lecture : plus la qualité augmente, plus le coût marginal par image progresse rapidement.
OpenAI ne facture plus à l’image forfaitaire. Chaque image est convertie en tokens selon sa résolution.
Formule. Coût total = (tokens de base) + (tokens par tuile x nombre de tuiles)
Exemple concret. Une image 512 x 512 consomme 210 tokens au total. 70 tokens de base plus 140 tokens de tuiles. Coût estimé 0,000263 $.
Coûts marginaux pour une 1024×1024. De 0,006 $ en qualité basse à 0,211 $ en qualité maximale. Range qui place le modèle en trajectoire d’accessibilité industrielle, tout en rendant chaque décision de qualité visible économiquement.
Coûts d’orchestration Responses API
La Responses API ajoute un coût d’orchestration via gpt-5.4.
| Contexte | Mode | Entrée | Sortie |
|---|---|---|---|
| Court | Standard | 2,50 $ / 1M | 15,00 $ / 1M |
| Court | Priority | supérieur | 30,00 $ / 1M |
| Long | Standard | 5,00 $ / 1M | 22,50 $ / 1M |
| Long | Batch | 2,50 $ / 1M | 11,25 $ / 1M |
Coûts d’outils additionnels
- Mode Réflexion avec recherche web. 10,00 $ pour 1000 appels.
- File Search. 2,50 $ pour 1000 appels, plus 0,10 $ par gigaoctet par jour (premier Go gratuit).
- Code Interpreter. Facturation à la session de 20 minutes, de 0,03 $ (1 Go RAM) à 1,92 $ (64 Go RAM).
- Clusters régionaux. Pénalité automatique de 10% sur l’ensemble de la facture pour résidence géographique des données.
Qualité vs coût : une montée non linéaire
Passer en haute qualité augmente fortement le coût. L’arbitrage dépend de l’usage : test rapide, visuel éditorial ou rendu final.
À retenir : la haute qualité coûte beaucoup plus cher que les niveaux Low et Medium. Elle doit donc être réservée aux images finales ou aux visuels à forte valeur.
16. Leviers d’optimisation
Quatre leviers à activer dès qu’on passe en production.
Cached input
Le levier économique le plus puissant. Conserver les images lourdes et les prompts récurrents dans le cache fait tomber l’ingestion de 8 $ à 2 $ par million de tokens en Standard. Rend l’édition itérative conversationnelle viable.
Mode Batch
50% de réduction sur tout (sauf exceptions) pour les traitements asynchrones 24h. Idéal pour production de masse non urgente (catalogues produits, variantes de campagnes, tests A/B).
Contexte court quand possible
Le prix des tokens d’orchestration double quand on passe en contexte long. Compacter l’historique via context_management et compact_threshold a un impact économique direct.
Priority uniquement pour les pics critiques
Le mode Priority (exécution sans attente durant les pics réseau) coûte 2x le Standard en sortie. À réserver aux moments où la latence est non négociable (live, production urgente client).
Partie VI. Pratique créative
17. Anatomie d’un bon prompt
Dix principes qui distinguent un prompt qui marche d’un prompt qui tâtonne.
- Nommer la fonction avant le style. « Affiche événementielle » avant « photoréaliste ». La fonction dicte la structure.
- Préciser les ratios et formats dès le prompt. Gagne une itération sur le recadrage.
- Structurer le texte voulu entre guillemets. Le modèle restitue mieux les chaînes délimitées.
- Donner une hiérarchie typographique. Titre, sous-titre, accroche, corps. Le modèle compose en conséquence.
- Décrire l’éclairage avant la palette. Lumière d’abord, couleur ensuite. Conforme au raisonnement du modèle.
- Ancrer dans une référence plutôt qu’un adjectif vague. « Style Saul Bass » vaut mieux que « style vintage ».
- Limiter les adjectifs empilés. Trois qualificatifs bien choisis valent mieux que douze approximatifs.
- Définir ce qu’on ne veut pas seulement si nécessaire. Les négations fonctionnent mais alourdissent.
- Tester en Instantané, valider en Réflexion. Ne jamais brûler du Réflexion sur un prompt non verrouillé.
- Sauvegarder les prompts qui marchent. Le prompt devient un actif, comme un preset dans Lightroom.
Exemple avant / après
Avant. "Une image futuriste et cool avec du texte."Après. "Affiche de conférence tech format 1024x1536, titre 'Futures Protocol' en Druk Wide noir sur fond bleu nuit, sous-titre 'Paris 2026' en Neue Haas Grotesk blanc plus petit, éclairage type néon latéral gauche, composition minimaliste avec 70% de vide autour du texte."18. Dix cas d’usage décortiqués
Affiche éditoriale magazine
Prompt type. "Affiche éditoriale format 2:3, style couverture magazine culture, titre principal en Didone forte chasse, accroche en sans-serif condensée, illustration centrale photographique avec traitement granuleux, palette crème et bordeaux."Piège courant. Le texte peut déborder sur l’illustration. Mieux vaut préciser une zone de respiration.
Maquette d’interface utilisateur
Le modèle excelle sur les mockups photoréalistes d’applications. Boutons, menus, en-têtes, cartes produit, tableaux de bord. Production instantanée de maquettes crédibles pour réunion de brief, avant même toute entrée dans Figma.
Infographie dense
Diagrammes scientifiques ou pédagogiques. Cycle de l’eau, architecture logicielle, chronologie historique. Le Mode Réflexion est particulièrement utile ici pour vérifier la précision factuelle.
Campagne multilingue
Un même visuel décliné en 6 langues à partir d’un point central. Le modèle adapte la composition au sens de lecture (arabe en RTL) et à la densité typographique.
Bannière web et social
Ratios 16:9, 1:1, 9:16 livrés directement. Fin des recadrages qui cassent la composition.
Illustration de presse
Format 3:2 classique. Le modèle compose avec l’espace de légende implicite.
Visuel de marque cohérent
Avec l’édition multi-tours via File ID, on peut produire une série cohérente. Utile pour lignes éditoriales de marque, calendriers social media, catalogues.
Pitch et présentation
Fonds de slides sur mesure, illustrations de concepts abstraits, diagrammes d’ouverture. La cohérence stylistique sur une série de 20 slides devient accessible.
Hero shot publicitaire
Mode Réflexion obligatoire. C’est le cas où la qualité absolue justifie le coût.
Storyboard statique
Pour AI films ou briefs de tournage, générer une série de vignettes en maintenant personnages et décors cohérents via la Responses API.
Partie VII. Stratégie pour directions créatives
20. La nouvelle taxinomie du travail créatif
GPT-Image-2 modifie ce qui a de la valeur dans la chaîne de production visuelle. Trois mouvements à observer.
Ce qui perd de la valeur
L’exécution matricielle répétitive. Détourage, équilibrage colorimétrique de base, variantes de format, production d’asset standards pour réseaux sociaux, mockups de proposition. Le temps humain investi là-dessus ne se justifie plus économiquement dans la plupart des cas.
Ce qui se déplace
Le rôle d’exécutant graphique se déplace vers un rôle d’architecte de prompt. La compétence technique (maîtrise d’Illustrator, de Photoshop) reste utile mais devient secondaire face à la compétence d’écriture. Savoir décrire une image, la structurer, l’itérer.
Ce qui prend de la valeur
Quatre compétences rares qui deviennent stratégiques.
La direction créative au sens fort. Savoir ce qu’il faut faire, pas comment l’exécuter. Sens, narration, cohérence de marque. Le modèle exécute, il ne décide pas.
L’ingénierie de prompts contextuels. Construire des systèmes de prompts qui produisent une signature visuelle cohérente sur des dizaines ou centaines d’images.
La supervision de la logique d’itération. Savoir quand laisser le Mode Réflexion itérer, quand intervenir, quand basculer entre les modes.
L’orchestration via API. Transformer un travail créatif en pipeline automatisé. Passage du service artisanal au système produit.
21. Comment intégrer GPT-Image-2 dans un studio
Une feuille de route pragmatique pour les 90 premiers jours.
Jours 1 à 15. Phase de découverte
Accès à ChatGPT Pro pour un ou deux directeurs de création. Test du Mode Réflexion sur des briefs passés. Constitution d’une bibliothèque de prompts qui marchent.
Livrable. Une note interne de 5 pages qui documente ce que le modèle fait bien et ce qu’il ne fait pas pour votre type de production.
Jours 15 à 45. Vérification d’organisation et premier pilote API
Lancement de la procédure KYC OpenAI. Intégration d’un ou deux flux de travail simples en Image API (par exemple génération de variantes de bannières). Mise en place du suivi des coûts.
Livrable. Un prototype de pipeline qui remplace une tâche récurrente identifiée.
Jours 45 à 90. Industrialisation progressive
Passage à la Responses API pour les flux qui bénéficient de la gestion d’état. Mise en place d’une librairie interne de prompts versionnés. Formation des équipes création et production.
Livrable. Une capacité de production identifiée comme scalable, avec coûts et qualité mesurés.
Gouvernance IP à verrouiller en parallèle
Clarifier par écrit avec les clients.
- Qui possède les prompts utilisés pour produire les visuels.
- Qui possède les images générées.
- Quelles garanties sur le training data et les risques de similarité.
- Quelles contraintes de mention de l’usage d’IA.
OpenAI fournit des conditions commerciales standards. Ne pas les accepter passivement. Les négocier en fonction de la nature du travail.
22. Limites et angles morts
Connaître les limites protège des promesses excessives.
Transparence native limitée. Le paramètre background accepte « transparent » mais la documentation souligne qu’une vraie transparence sans fond reste une limitation. Le détourage post-génération reste souvent nécessaire.
Cohérence extrême multi-tours. Sur des séries longues (30+ images), même la Responses API peut dériver. Prévoir des points d’ancrage réguliers, des File IDs de référence rappelés.
Reproductibilité pixel-parfaite. Deux générations avec le même prompt ne donnent pas la même image. Pour une reproduction exacte, il faut sauvegarder le résultat, pas le prompt.
Droits sur personnages réels. Le modèle refuse de générer des images réalistes de personnes publiques connues. Comportement attendu et prudent, à intégrer en amont du brief.
Qualité sur langues sous-représentées. Voir le tableau de la section 3. Un projet majoritairement swahili ou amharique demandera plus d’itérations ou des passages par l’éditeur.
Animation et vidéo. Le modèle est statique. La fermeture de Sora laisse un trou que d’autres acteurs tentent de combler (Runway, Kling, Veo).
Clôture
23. Perspective 12 mois
Quatre tendances probables à surveiller d’ici avril 2027.
Convergence image-vidéo. La fermeture de Sora n’est probablement pas définitive dans l’intention. OpenAI va réintroduire de la vidéo, mais par la porte de l’image contrôlée (image-to-video, édition de keyframes). Surveiller les annonces sur cette jonction.
Fine-tuning accessible. gpt-image-2 offrira probablement un mécanisme de fine-tuning léger pour les organisations qui veulent imposer une signature visuelle sans entraîner un LoRA complet. Cela déplacera la valeur vers les bibliothèques de références propriétaires.
Concurrence commoditisée. Google Nano Banana, Midjourney, Ideogram, Flux. La bataille des modèles d’image va continuer. La différence se fera moins sur la qualité brute que sur l’intégration dans les flux de travail et l’écosystème d’API.
Régulation en resserrement. La vérification d’identité institutionnelle est un signal. D’autres garde-fous vont arriver (watermarking obligatoire, traçabilité). Les studios qui intègrent la conformité dès maintenant prennent une longueur d’avance.
24. Ressources et prochaines étapes
Documentation officielle
Trois prochaines étapes concrètes
Si vous êtes directeur ou directrice de création. Testez le Mode Réflexion sur un brief réel cette semaine. Comparez avec votre flux habituel. Documentez la différence en une page.
Si vous êtes équipe marketing ou communication. Choisissez un asset récurrent (bannière hebdo, visuel social, mockup). Passez-le en pipeline gpt-image-2. Mesurez temps gagné et qualité perçue sur 30 jours.
Si vous êtes studio ou agence. Lancez la vérification d’organisation API maintenant. Le délai administratif ne doit pas être sur le chemin critique de votre premier projet.
Aller plus loin avec CreativeAI.fr
Formations sur mesure pour équipes créatives sur GPT-Image-2, systèmes de prompts, workflows et intégration en production. Finançables OPCO. Programmes certifiés Qualiopi.
Contact • Formations →
Annexes
Annexe A. Cheatsheet paramètres API
# Paramètres les plus utiles en un coup d'œil
client.images.generate(
model="gpt-image-2", # ou gpt-image-1.5, gpt-image-1-mini
prompt="...", # langage naturel, fonction avant style
size="1024x1024", # multiple de 16, max 3840
quality="high", # low | medium | high | auto
output_format="png", # png | jpeg | webp
output_compression=85, # 0 à 100 pour jpeg et webp
background="opaque", # opaque | transparent (limité)
moderation="auto", # auto | low
n=1 # 1 à 10 images par requête
)
Annexe B. Glossaire
Diffusion. Famille d’algorithmes génératifs qui partent d’un bruit aléatoire et le transforment progressivement en image selon un prompt.
Fenêtre de contexte. Mémoire maximale du modèle en tokens. 272 000 pour gpt-5.4 utilisé par la Responses API.
File ID. Identifiant persistant d’un fichier uploadé sur OpenAI. Permet de référencer une image dans une conversation multi-tours sans la re-uploader.
In-painting. Technique d’édition localisée où le modèle régénère une zone masquée d’une image existante selon une instruction.
LoRA (Low-Rank Adaptation). Technique de fine-tuning léger qui permet d’injecter une signature esthétique dans un modèle sans le réentraîner complètement.
Mode Réflexion. Mode d’exécution premium où le modèle auto-évalue ses sorties et itère internement avant de livrer.
Prompt. Spécification textuelle qui décrit l’image voulue.
Responses API. Endpoint OpenAI d’orchestration multimodale avec gestion d’état, tool calling et gestion de contexte.
Tile (tuile). Unité de décomposition d’une image pour la facturation par tokens.
Token. Unité de facturation et de mesure du contexte. Environ 4 caractères pour du texte. Calculé différemment pour une image selon sa résolution.
Tool calling. Mécanisme qui permet à un modèle de langage d’invoquer des outils externes (génération d’image, recherche web, code) comme partie de sa réponse.
Annexe C. FAQ courte
Peut-on utiliser gpt-image-2 commercialement ? Oui, après vérification d’organisation API. Les images générées sont utilisables commercialement selon les conditions OpenAI en vigueur.
Quelle différence avec DALL-E ? gpt-image-2 est le successeur direct. DALL-E est déprécié, remplacé par la famille gpt-image.
Peut-on entraîner gpt-image-2 sur ses propres images ? Pas encore publiquement. OpenAI ouvrira probablement un mécanisme de fine-tuning léger dans les mois à venir.
Le modèle peut-il générer des images avec des personnes réelles célèbres ? Non, par conception. Les personnages publics sont bloqués pour des raisons éthiques et juridiques.
Combien coûte en moyenne une image de qualité commerciale ? Entre 0,05 $ et 0,21 $ en qualité high pour une 1024×1024 en Mode Instantané. Mode Réflexion peut multiplier par 5 à 10.
Peut-on générer des images transparentes natives ? Partiellement. Le paramètre existe mais donne des résultats inégaux. Un détourage post-production reste souvent nécessaire.
Directeur de création · 20+ ans d’expérience en agence (Marcel, Leo Burnett). 600+ professionnels formés aux méthodes & workflows IA depuis 2023. Formations certifiées QUALIOPI.
formations IA
Google Flow, Veo & Gemini Omni : L’Orchestration Cinématographique IA NEW
Durée : 2 jours (14h). Public : DA, réalisateurs, motion designers, équipes marketing, communication et social media
Réinventer son processus créatif avec l’IA générative
Durée : 5 jours (35h). Public : DA, graphistes, designers
Gemini & Nano Banana 2 : du brief à l’image finale
Durée : 1 jour (7h). Public : graphistes, designers, drecteurs artistiques
L’IA générative pour les créatifs : panorama et expérimentation des outils essentiels
Durée : 1 jour (7h). Public : DA, dirigeants, designers
Content Factory Pilot 30 jours : construire un système éditorial IA réellement utilisable
Durée : 30 jours (accompagnement). Public : dirigeants, équipes marketing & communication
Creative Memory Sprint : construire la mémoire IA créative de votre agence
Durée : 3 à 4 semaines (accompagnement). Public : directions créatives, studios créatifs, équipes marketing
Explorer la Bible Photographique

Pellicules argentiques en prompt IA
Il y a quelque chose de paradoxal à utiliser le nom d’une pellicule argentique pour guider un modèle d’intelligence artificielle. Et pourtant, c’est l’une des techniques les plus efficaces qui existe.

Références de photographes pour prompts IA
Écrire in the style of Richard Avedon dans un prompt IA n’est pas une métaphore. C’est une instruction technique.

Guide complet des focales pour Midjourney, Flux et ChatGPT ImageS
La distance focale est probablement le paramètre technique le plus sous-utilisé dans les prompts IA. Pourtant, une focale bien choisie transforme la géométrie d’une image, la compression de l’espace, la relation entre le sujet et son environnement.
La Bible Photo intégrale
pour Prompts IA
Cette bible est la référence de vocabulaire photographique pour la génération d’images par IA. Elle couvre l’ensemble du lexique (optique, éclairage, composition, pellicules, esthétiques, colorimétrie) et indique pour chaque terme un exemple de prompt concret et son niveau d’efficacité sur les principaux modèles.

Derniers articles
-
Pourquoi les formations IA généralistes échouent à répondre aux métiers créatifs
Les formations IA généralistes donnent souvent une bonne première culture des outils. Mais elles échouent quand il faut produire, décliner,…
-
Diriger l’émotion, l’expression et le mouvement dans les images et films IA
Diriger une émotion en IA ne consiste pas à empiler des adjectifs, mais à écrire une partition précise : les…
-
Pourquoi votre équipe marketing n’a pas besoin de plus d’outils IA, mais d’un système éditorial
Le contenu ne manque pas toujours d’idées. Il manque souvent d’un système pour transformer ces idées en publications régulières, utiles…